
J'avais l'intention de parler de GraphQL depuis un moment. L'idée est de montrer, de la manière la plus réaliste possible, l'utilisation de cette technologie.
En créant le projet d'exemple, j'ai fini par inclure des éléments vraiment intéressants, qui s'intègrent très bien dans des projets réels. Attendez-vous donc à trouver de bons exemples avec les technologies suivantes :
- Bogus ;
- HotChocolate ;
- Entity Framework Core ;
- Injection de dépendances ;
- Pagination avec GraphQL ;
- Requêtes ;
(le code source sera disponible sur GitHub. Le lien se trouve à la fin de cet article)
Un peu d'histoire sur GraphQL
Tout d'abord, qu'est-ce que GraphQL ?
« GraphQL est un langage de requête pour les API et un runtime pour exécuter ces requêtes avec vos données existantes. GraphQL fournit une description complète et compréhensible des données de votre API, donne aux clients le pouvoir de demander exactement ce dont ils ont besoin et rien de plus, facilite l'évolution des API au fil du temps, et permet des outils puissants pour les développeurs. »
C'est la définition formelle de GraphQL, qui se trouve sur le site officiel, mais revenons un peu en arrière. GraphQL est apparu en 2012, issu d'un projet interne de Facebook, mais il a été publiquement lancé en 2015.
En 2018, il a finalement été transféré à la GraphQL Foundation, une organisation à but non lucratif sous Linux. Son créateur, Lee Byron, affirme que le produit a suivi son objectif depuis le début et qu'il est omniprésent sur toutes les plateformes web.
Le projet a vu le jour parce qu'Apple a concentré toutes ses ressources sur les applications mobiles natives, tandis que Google ne se préoccupait pas beaucoup de l'expérience utilisateur dans les applications web/mobiles. La même année, Facebook a construit son application, misant fortement sur HTML5 (grosse erreur, selon Mark Zuckerberg), mais la transition du web au marché mobile n'était pas assez mature. Facebook a donc embauché de nombreux ingénieurs iOS seniors et a décidé de réécrire toute l'application pour iOS, en commençant par le fil d'actualité.
En standard, ils ont utilisé une API RESTful, ce qui a entraîné plusieurs problèmes :
-
Lenteur du réseau : l'API ne pouvait pas renvoyer toutes les données, obligeant le client à faire de plus en plus de requêtes à différentes API ;
-
Problèmes de documentation : en raison de la complexité et du nombre d'implémentations, la documentation était parfois obsolète ;
-
Maintenance de l'application : concernant les réponses de l'API, si l'API changeait son format de réponse, le code du client devait changer en conséquence. Les ingénieurs devaient manuellement maintenir les classes de modèle client, la logique réseau et d'autres éléments pour s'assurer que les bonnes données étaient chargées au bon moment avant de rendre l'affichage.
Avantages et inconvénients ?
Mais qu'est-ce vraiment que GraphQL ? Quels sont ses avantages et ses inconvénients ?
La réponse est simple : GraphQL est un langage de requête utilisé pour récupérer uniquement les données que le client souhaite de la base de données.
Avantages :
-
Vitesse du réseau : contrairement à l'approche RESTful, GraphQL ne renvoie que ce dont le client a besoin. Cela diminue le nombre d'appels et la taille des requêtes ;
-
Types statiques robustes : permet aux clients de savoir quelles données sont disponibles et de quel type de données il s'agit ;
-
Facilitation de l'évolution des clients : le format de la réponse est entièrement contrôlé par la requête du client. Par conséquent, le code côté serveur devient beaucoup plus simple et plus facile à maintenir. Lorsque vous supprimez d'anciens champs d'une API, ces champs seront dépréciés, mais continueront de fonctionner. Ce processus graduel de compatibilité descendante élimine le besoin de versionnage. Après toutes ces années, Facebook utilise toujours la version 1 de son API GraphQL ;
-
Documentation : la documentation est générée automatiquement et toujours à jour ;
-
Code de requête arbitraire : GraphQL est adaptable. Il ne concerne pas les bases de données. Il peut être adopté au-dessus d'une API RESTful existante et peut fonctionner avec les outils de gestion d'API existants.
Inconvénients:
-
Courbe d'apprentissage : si vous connaissez déjà REST, vous pouvez rencontrer des difficultés dans son implémentation ;
-
Mise en cache : elle est plus difficile avec GraphQL ;
-
Requêtes : elles renvoient toujours le code 200.
Assez de bavardages ! Passons à l'action !
- Créons un projet API :

- Sélectionnez le type de projet "ASP.NET Core Web API" :

- Entrez un nom pour votre solution :

- Sélectionnez la version ".NET 6.0 LTS", gardez les autres options telles qu'indiquées et cliquez sur "Create" :

- La structure de la solution devrait ressembler à ceci :

- Créez les dossiers suivants :

-
Data : où nous créerons les classes qui peupleront notre base de données SQL Server (seeds). Ce dossier doit également contenir la classe de contexte ;
-
GraphQL : où se trouvent les fichiers Queries et Mutations, que nous aborderons plus tard ;
-
Interfaces : comme le nom l'indique, c'est là que nous créerons une interface pour gérer nos services ;
-
Migrations : créé automatiquement lorsque nous exécutons la migration ;
-
Models : où nous devons créer nos classes de modèles concrets ;
-
Services : doit contenir la classe de service concrète, qui doit implémenter l'interface créée précédemment ;
-
ViewModels : juste une classe de transport.
7. Maintenant, installons les packages nécessaires pour ce projet :
- Install-Package Bogus
- Install-Package HotChocolate.AspNetCore
- Install-Package HotChocolate.Data.EntityFramework
- Install-Package Microsoft.EntityFrameworkCore
- Install-Package Microsoft.EntityFrameworkCore.SqlServer
- Install-Package Microsoft.EntityFrameworkCore.Tools
- Install-Package Microsoft.EntityFrameworkCore.Abstractions
- Install-Package Microsoft.EntityFrameworkCore.Design
- Install-Package Microsoft.EntityFrameworkCore.Relational
8. Créons maintenant les classes "Customer" et "Invoice" dans le dossier "Models".
Tout d'abord, créons les deux classes qui représenteront notre modèle. L'objectif est d'avoir une classe appelée "Customer" et une autre appelée "Invoice". Cette dernière est une liste de factures par client (nous simulerons plusieurs clients), qui ont une séquence aléatoire de factures. Cela sera créé automatiquement en utilisant certaines fonctionnalités géniales (nous y viendrons).
Classe Client
Créez d'abord une interface dans le dossier "Interfaces" appelée "IAggregateRoot":
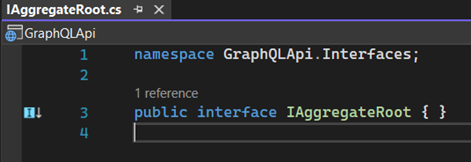
Nous avons deux constructeurs dans la classe "Customer" - le premier est utilisé uniquement pour Entity Framework.
Nous pouvons également voir que la classe fait référence à "Invoice", que nous créerons dans la prochaine étape. Seule la classe "Customer" affichera une erreur jusqu'à ce que la classe "Invoice" soit créée.
J'ai utilisé quelques techniques importantes :
- Notez que la classe "Customer" implémente une interface appelée "IAggregateRoot", où sa seule fonction est d'être une interface de balisage. C'est une bonne pratique très utilisée dans les projets qui utilisent la conception DDD. Elle est utilisée pour montrer que "Customer" est une racine d'agrégation. Cette technique garantit la cohésion, l'expressivité et l'intégrité du domaine, puisque l'accès à ces entités ne peut se faire que depuis l'entité racine, qui dans notre cas est "Customer". Il est important de prendre en considération qu'il ne s'agit que d'une démonstration - en pratique, cette technique s'applique aux projets plus importants qui ont plus de contextes ;
- Une autre fonctionnalité importante est la configuration des propriétés de classe, en les décorant avec des validations. En utilisant les annotations de données, nous pouvons créer des validations directement dans la classe, ce qui nous aidera à définir les champs requis, les plages, les tailles de champ, les comparaisons de dates, regex et bien plus encore ;
- Tous nos "set" sont privés, cachés du monde extérieur, donnant à la classe elle-même la responsabilité de la création d'une nouvelle instance. De cette façon, nous garantissons la condition de notre classe et il ne sera possible de la modifier que par les méthodes fournies par elle.
J'ai saisi l'occasion pour indiquer la clé primaire et la relation que nous aurons - 1: N - avec la classe "Invoice". Personnellement, je ne crée pas de cette manière. Dans des projets plus importants, il est logique de créer des classes de mappage correctement séparées - en outre, la classe concrète obtient un code plus propre et plus facile à comprendre.
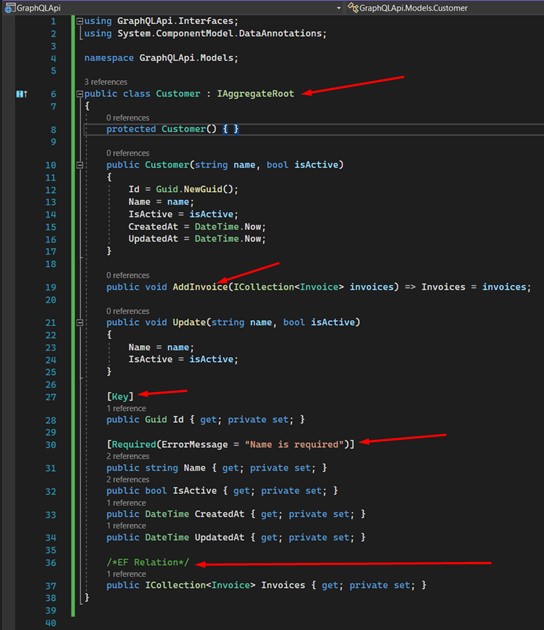
Classe Invoice
Très similaire à la classe "Customer" en termes de structure. Les lignes 35, 36 et 37 font référence à la classe "Customer" dans le but de créer les tables et leurs relations utilisées dans Entity Framework.

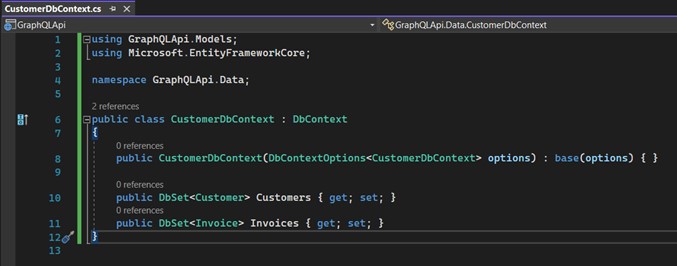
9. Créez la classe "CustomerDbContext" à l'intérieur du dossier "Data". Elle héritera de "DbContext", qui fait partie d'Entity Framework. Fondamentalement, elle représente un type de session avec la base de données et, de cette manière, elle nous permet d'effectuer des requêtes, de sauvegarder des instances, etc.
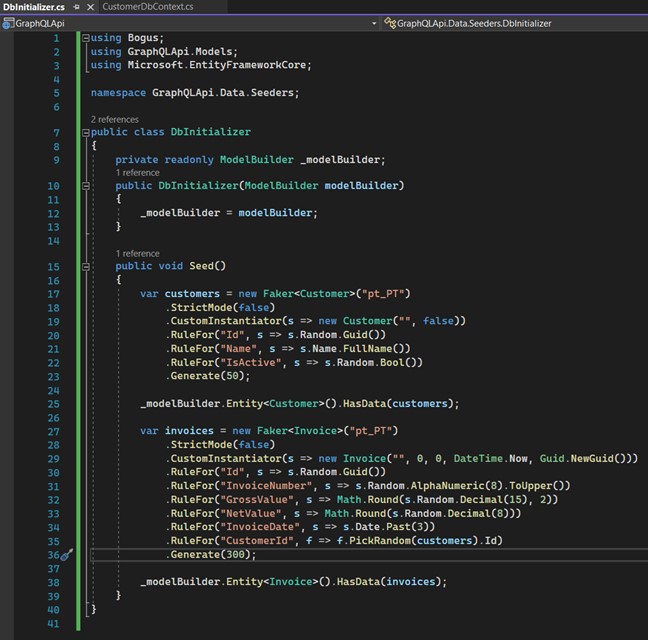
10. Créons des données automatiques avec Bogus. Le paquet « Bogus » est une ressource que j'utilise beaucoup dans mes projets. Il nous aide à créer des données factices d'une manière très intelligente et efficace, et possède de nombreuses méthodes qui s'adaptent à tous les types de génération de données, telles que les données financières, les dates, les données humaines comme la date de naissance, le sexe, les noms, les données mathématiques, et ainsi de suite...
Créez un dossier à l'intérieur du dossier "Data" et appelez-le "Seeders". À l'intérieur de ce dossier, créez une classe appelée "DbInitializer".
Voyez que la méthode "Seed" va créer une instance de "Customer". À la ligne 23, nous indiquons le nombre d'enregistrements que nous voulons créer et elle va créer un certain nombre de "Customers" de manière aléatoire. Les "Invoices" fonctionnent de la même manière, avec un détail important : à la ligne 35, la méthode "PickRandom" récupérera un "Customer" déjà créé pour relier les "Invoices".
C'est un excellent outil à utiliser dans les tests unitaires.
Maintenant, retournons à la classe "CustomerDbContext" et incluons l'appel à la classe "DbInitializer" dans la surcharge de la méthode "OnModelCreating", qui est exécutée chaque fois que nous exécutons la commande "update-database" d'une migration.

11. Enregistrez les fonctionnalités dans l'API. Ouvrez la classe "Program.cs" et incluez ces lignes. Ici, nous configurons notre DbContext dans l'application. Plus tard, nous modifierons à nouveau cette classe :
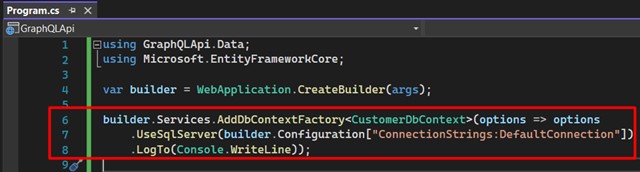
Notez que la ligne 7 fait référence à la chaîne de connexion, qui sera utilisée pour la persistance des données. Ouvrez donc le fichier "appsettings.json" et enregistrez la vôtre.
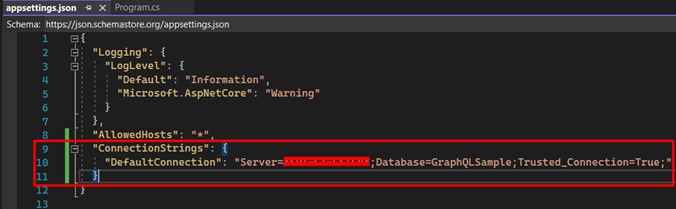
12. Ajoutez la migration : créez la base de données + les tables. Si tout s'est bien passé jusqu'à présent, c'est le bon moment pour exécuter deux commandes : la première créera la migration basée sur les "Models" et la suivante exécutera réellement les commandes SQL pour notre base de données.
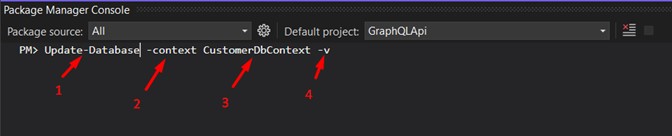
Dans la console Gestionnaire de packages, exécutez la première commande :
1 - Commande principale ;2 - Le nom qui identifie la migration (j'ai utilisé "initial") ;
3 - Paramètre qui identifie le contexte ;
4 - Nom du contexte ;
5 - Il signifie "Verbose", facultatif (je l'utilise toujours, car tout le processus sera plus détaillé dans la sortie).
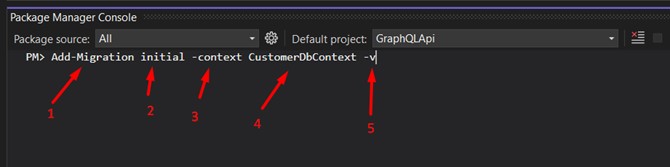
Si tout s'est bien passé, vous devriez voir un fichier similaire à celui-ci. Il est automatiquement généré avec chaque migration et contient toutes les commandes nécessaires pour créer/modifier notre base de données et ses tables, index, etc.
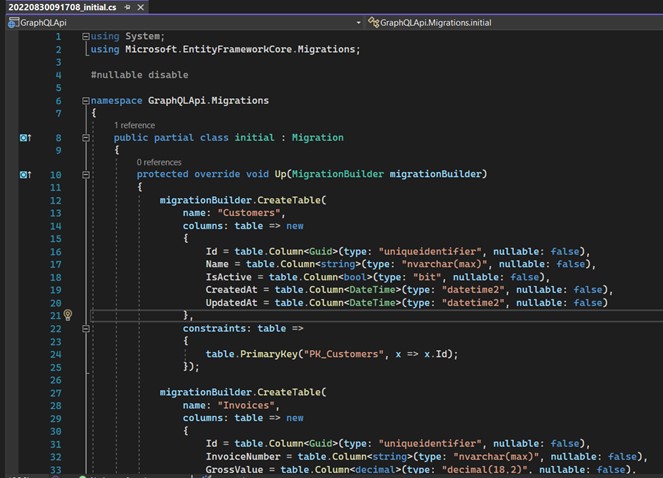
La deuxième commande est celle qui exécutera réellement les commandes sur la base de données.
- Commande principale ;
- Paramètre qui identifie le contexte ;
- Nom du contexte ;
- Il signifie "Verbose", facultatif (je l'utilise toujours, car tout le processus sera plus détaillé dans la sortie).
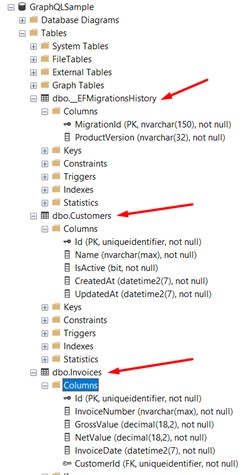
Ce dernier est très important, car c'est à ce moment que la classe "DbInitializer" sera appelée pour créer nos données "fictives". Tout cela se fait automatiquement. Ouvrez votre gestionnaire SQL Server et vérifiez si tout a été créé correctement.
Nous pouvons voir que 3 tables ont été créées : la première table dans l'image est la table de contrôle d'Entity Framework ; la deuxième est la table "Customers" ; et la troisième est la table "Invoices".
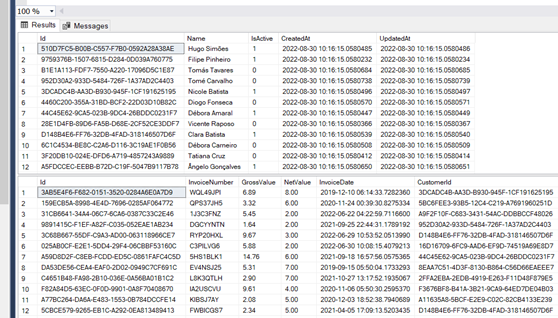
Les données ont déjà été créées comme le montre l'image :
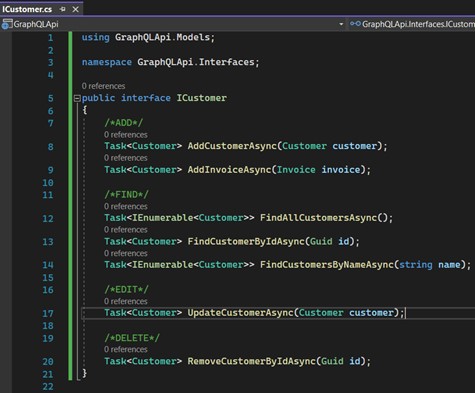
13. Passons à la création du service. Nous allons maintenant créer une interface "ICustomerService", qui devrait contenir les méthodes pour persister nos données :
Nous allons créer le service qui implémentera cette interface. Première partie : nous implémentons les méthodes pour inclure "Customer" et "Invoice" :
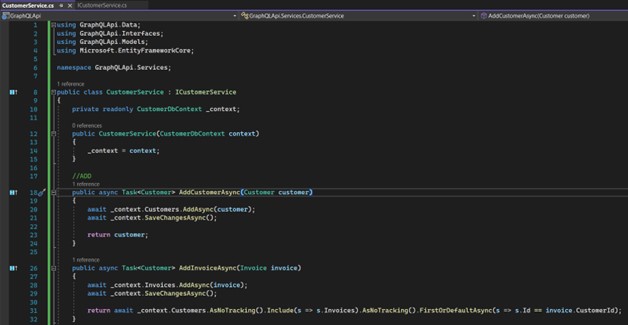
Ensuite, les méthodes pour obtenir, modifier et supprimer des données :
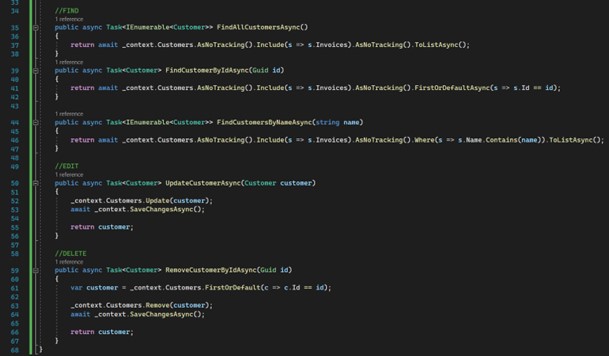
14. Enregistrez les services dans "Program.cs" :
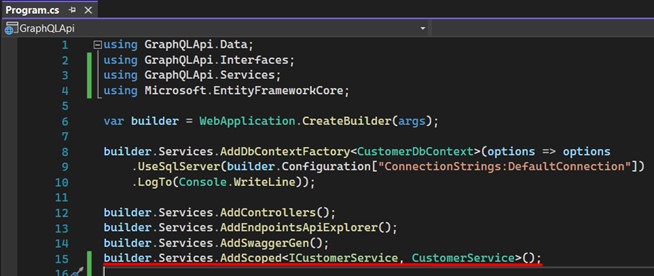
15. Maintenant, parlons enfin de GraphQL. Il y a deux opérations principales en GraphQL :
- Query : Utilisée pour les requêtes de données
- Mutation : Utilisée pour modifier les données.
Query
En pratique, Query fonctionne de manière fluide. Vous indiquez les champs que vous avez l'intention d'utiliser, mais sans avoir besoin d'avoir un modèle de vue dans le serveur pour chaque service que vous avez l'intention de consommer et de retourner des valeurs.
Exemple : À gauche, nous voyons un type de requête où, même si le service peut renvoyer 10 champs, je n'entre que ceux dont j'ai vraiment besoin. À droite, la liste des "animaux de compagnie" contenant uniquement les champs que j'ai demandés.

Cet autre exemple montre comment nous pouvons rechercher des données par code :

Mutations
Les mutations, comme leur nom l'indique, sont responsables de la modification des données. Chaque fois que nous voulons modifier, inclure ou supprimer des données, nous devrions utiliser ce type.
Exemple : Nous informons que nous voulons utiliser une mutation, puis ajoutons simplement la méthode précédemment configurée et les valeurs d'entrée. Cela suffirait pour inclure ces données.

16. Créons nos requêtes : créons un dossier appelé « Queries » à l'intérieur du dossier « GraphQL ». Créez ensuite une classe appelée « CustomerQuery », qui devrait ressembler à ceci :
Tout d'abord, réalisons le service de dépendance par injection qui renvoie les données. Ensuite, créons 3 méthodes : la première retournera tous les « Customers » ; la seconde devrait récupérer un « Customers » par Id ; et la troisième retournera les « Customers» en renseignant un nom.
17. Nous devons maintenant enregistrer GraphQL dans « Program.cs » :
18. Modifier la configuration du projet, dans les propriétés, en faisant un clic droit sur le projet, dernière option « Properties “, et en recherchant ” env ».
De cette manière, l'ouverture se fera à partir de la page :
Et exécutez votre application. Vous devriez obtenir une réponse comme celle-ci :
19. Passons à notre première requête. Cliquez sur « Create Document » et écrivez la requête suivante...
Et voilà ! Nous avons notre première requête réussie !
Quelques détails importants :
- Nous pouvons voir que j'informe « query » et juste après je peux donner un nom à cette requête. Dans mon cas « FindAll », je dis que je veux seulement « id », « name » et « createdAt ». La même chose s'applique à « Invoices ».
- Sur le côté droit, nous pouvons déjà voir le résultat, la liste des « Customers “ et leurs " Invoices » correspondantes.
20. Nous pouvons maintenant effectuer une recherche par « Name » (nom).
Exemple : en recherchant seulement « Customers » qui contiennent le nom « Carlos », la première image est la recherche et juste en dessous nous pouvons voir la méthode qui a été utilisée sur le serveur. Vous voyez que maintenant je n'apporte que 3 champs du client :

21. Effectuons maintenant une recherche par numéro d'identification. Prenons un numéro d'identification aléatoire dans la table « Customer ». Vous voyez que je n'ai ramené que les données concernant le « Customer “ avec l'Id = ” 44C45E62-9CA5-023B-9DC4-26BDDC0231F7 » :
22. Maintenant, une astuce précieuse : mettons en place une pagination pour visualiser nos « Customers ». Créez une méthode comme celle-ci :
Nous agrémentons d'abord notre méthode avec l'attribut qui nous permet d'accéder au contexte pour GraphQL. Juste après, un autre attribut qui configure l'utilisation de la pagination.
Il existe 2 types de pagination :
1) UsePaging : l'intergiciel renvoie un curseur qui doit être utilisé ultérieurement pour chaque appel. Il passe ainsi aux pages suivantes ;
2) UseOffsetPaging : modèle plus traditionnel, où les métadonnées contenant le numéro de page, la taille de la page, et d'autres que nous verrons, sont renseignées et renvoyées.
Exécutez l'application et faites une nouvelle requête, comme celle-ci :
Observez la séquence :
1 - Renseignez les paramètres « skip » et « take » qui représentent respectivement la page et le nombre d'éléments par page ;
2 - « PageInfo » est fourni par GraphQL ;
3 - « Items » est la liste des éléments retournés en fonction des paramètres renseignés ;
4 - Le retour avec « PageInfo » rempli ;
5 - Dans la console, nous pouvons voir la requête qui a été exécutée dans le serveur SQL. La requête renvoie-t-elle ce dont nous avons besoin ? Oui. Est-elle correcte ? Non.
Nous avons encore un problème : imaginons une table avec 50.000 éléments. Même si nous mettons en œuvre la pagination, elle n'est appliquée qu'après que la requête a déjà été faite à la base de données. Donc, de la manière dont c'est implémenté, pour chaque requête sera obtenu et paginé, à chaque fois, 50.000 enregistrements. Cela ne manquera pas d'entraîner un gros mal de tête en termes de performances. Cela est dû au fait que nous utilisons un « IEnumerable » comme forme de recherche, ce qui signifie que la requête est d'abord effectuée dans la base de données, puis filtrée en mémoire.
23. Pour résoudre le problème de la pagination, modifiez la méthode pour qu'elle ressemble à ceci :
Voyez qu'il renvoie un « IQueryable », qui interroge la base de données en utilisant des paramètres de filtrage/pagination, en ne ramenant en fait que les données dont nous avons besoin.
Le résultat est le même, mais nous pouvons voir que la commande SQL Server reçoit déjà les paramètres directement dans la requête.
24. Créons nos mutations. Rappelez-vous que les « mutations » sont utilisées lorsque nous avons besoin de changer l'état de nos entités, que ce soit pour l'édition/l'inclusion/la suppression.
La première chose à faire est de créer un dossier appelé « Mutations » dans le dossier « GraphQL ». Dans ce nouveau dossier, nous créons la classe « CustomerMutations.cs ».

Dans le dossier « ViewModels », nous devons créer deux modèles de vue : « CustomerViewModel » et « InvoiceViewModel », utilisés pour recevoir les paramètres des requêtes.

La classe « CustomerMutation », tout comme la Query, contiendra le code responsable de la consommation du service « CustomerService ».
Ainsi, nous pouvons voir que nous avons maintenant les méthodes « AddCustomerAsync », « UpdateCustomerAsync » et « DeleteCustomerAsync ».
25. Enregistrons la mutation. Toujours dans « Program.cs », nous allons inclure le code suivant. Modifiez votre AddGrapQLServer pour qu'il contienne votre mutation :
26. Ajout d'un enregistrement :
27. Inclure une "Invoice":
28. Modification d'un enregistrement :
29. Suppression d'un enregistrement :
Conclusion
GraphQL est une excellente option pour la création d'API. Les performances sont excellentes, et nous avons moins de fichiers dans le projet, puisque nous n'avons pas besoin de créer de multiples endpoints. Cela permet au client (Mobile, Web, Angular, React) d'avoir plus de liberté concernant l'utilisation et le traitement des requêtes, et de ne pas être aussi dépendant du côté serveur.
Il est également important de comprendre le type de projet et de savoir si votre équipe est prête à travailler avec GraphQL comme elle le fait avec REST.
Liens utiles :
- Github: Github Leosul GraphQL
- LinkedIn: LinkedIn GraphQL Article
- Medium: Medium GraphQL Article
Sources:
