
Qu'est-ce qu Apache Kafka?
Apache Kafka est une plateforme open-source de streaming d'événements distribuée qui offre de hautes performances pour l'analyse, l'intégration/transformation des données pour les applications en temps réel ou quasi temps réel, et est utilisée par de nombreuses entreprises dans le monde entier.
Il fonctionne selon une méthode de publication-abonnement qui stocke, traite (si nécessaire) et délivre des données aux abonnés ou consommateurs. Kafka est extrêmement rapide et peut gérer des centaines de mégaoctets par seconde, avec des centaines de milliers de messages par seconde, avec une latence aussi faible que 2 millisecondes (ms).
Qu'est-ce que le streaming d'événements ?
Le streaming d'événements désigne la capacité à collecter des données à partir d'une ou plusieurs sources - comme des capteurs IoT, des bases de données ou des applications -, à les stocker temporairement pour une récupération ultérieure, et à les traiter, manipuler ou acheminer vers différentes destinations, en fonction des besoins. Ce processus peut se dérouler en temps réel et impliquer diverses technologies.
Qui utilise Kafka ?
Parmi les utilisateurs figurent des banques, des bourses, des usines, le secteur du commerce de détail, des applications mobiles, et bien d'autres. Il est important de noter qu'Apache Kafka n'est pas adapté à tous les cas d'utilisation !
Il existe différentes variantes d'implémentation (plus petites, plus grandes), mais le temps réel est coûteux. Pour les cas où des milliers d'événements par seconde sont générés, traités et consommés, Apache Kafka est une bonne option en raison de son architecture robuste et fiable. Cependant, héberger un cluster Kafka soi-même ou payer pour une solution de service Apache Kafka hébergée dans le cloud peut représenter un coût significatif.
Pourquoi est-il important de connaître Kafka ?
Tout le monde n'a pas la chance de travailler directement avec Apache Kafka, mais de nombreuses solutions l'utilisent en coulisses, et il est utile d'avoir une idée de son fonctionnement.
En effet, Apache Kafka est utilisé par plus de 80 % des 100 meilleures entreprises où il fait bon travailler selon Fortune. Parmi ces grandes entreprises, on trouve, selon Kafka, The New York Times, Pinterest, Adidas, Airbnb, Coursera, Cisco, La Redoute, LinkedIn, Netflix, Oracle, PayPal, Spotify, Tumblr, Yahoo, et bien d'autres.
Comment fonctionne Kafka ?
Imaginez un événement, tel qu'un message de notification, une mesure de température ou des coordonnées GPS. Ces événements peuvent être générés par des utilisateurs ou des applications, comme un tweet sur une application comme X (anciennement Twitter). Ils peuvent ensuite être lus, utilisés ou consommés par d'autres utilisateurs ou applications.
Dans le monde de Kafka, ces événements sont produits par des "producteurs" et consommés par des "consommateurs". Ils sont générés et stockés dans des "sujets", qui sont des canaux de communication entre producteurs et consommateurs. Pour gérer efficacement un grand nombre d'événements, Kafka utilise une architecture distribuée, où les sujets sont divisés en "partitions" et répartis sur plusieurs "courtiers" (serveurs Kafka).
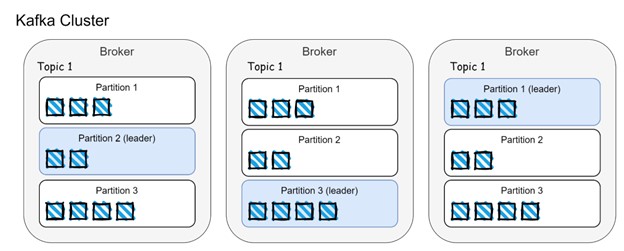
Dans l'image ci-dessus, nous pouvons voir la distribution des données entre les courtiers et les partitions. Les événements sont répartis entre les partitions et répliqués sur les courtiers. Le leader de la partition est responsable de la gestion des événements entrants des producteurs et des demandes de client des consommateurs. Les autres suiveurs de la partition (d'autres courtiers) répliquent les données des partitions leaders et garantissent que les réplicas (courtiers) sont synchronisés, également connus sous le nom de réplica en synchronisation (ISR).
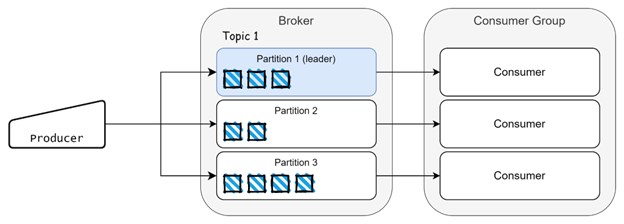
Les événements sont consommés par des consommateurs et nous pouvons également avoir des groupes de consommateurs, qui répartissent la charge de travail lorsqu'une grande quantité de données est générée. Chaque événement stocké sur une partition a une position et est connu sous le nom d'offset, comme une position dans un tableau.
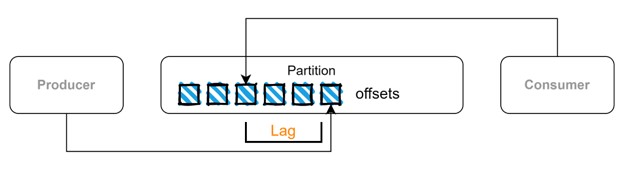
Il existe un scénario où toutes les données produites ne sont pas consommées par les consommateurs, et cela pourrait se produire pour différentes raisons. En revenant à l'exemple de l'application X, nous pourrions ne pas être en mesure de consulter tous les tweets publiés sur la plateforme, nous aurons donc des tweets non lus. La même chose peut se produire avec Kafka et cela est connu sous le nom de retard du consommateur. Les événements sont stockés dans des partitions dans une séquence, chaque événement ayant un décalage (une position dans une partition), et ces informations sont stockées sur des sujets internes qui contiennent des métadonnées. Ainsi, Apache Kafka "sait" quels événements ont été consommés ou non, et ce retard pourrait être un indicateur de problèmes de performance.
Pour orchestrer tout cela, Apache Kafka a une dépendance principale appelée Zookeeper. Il garde une trace des données du cluster et coordonne les courtiers, les groupes de consommateurs et les élections. C'est une condition préalable pour certains types de déploiement du cluster Kafka et doit exister avant l'installation des courtiers Kafka. Vous pouvez avoir plusieurs réplicas Zookeeper dans votre cluster Kafka pour garantir une haute disponibilité.
Intégration avec d'autres systèmes
Kafka offre la possibilité de partager des flux de données avec d'autres systèmes via Kafka Connect, une boîte à outils d'intégration dotée de plugins adaptés aux connecteurs. Ces plugins permettent la conversion et la transformation des données.
L'architecture de Kafka Connect repose sur des connecteurs chargés de créer des tâches. Ces tâches, utilisées pour déplacer les données, sont exécutées par des travailleurs. Par ailleurs, des transformateurs et des convertisseurs sont mis en œuvre pour manipuler et transformer les données, respectivement.
Il existe deux catégories de connecteurs :
-
Les connecteurs source, qui récupèrent les données depuis d'autres sources, les transforment et les stockent dans des sujets Kafka. Par exemple, les données provenant d'une table de base de données relationnelle peuvent être extraites, converties au format JSON et placées dans un sujet Kafka.
-
Les connecteurs de destination, qui extraient les données des sujets Kafka, les transforment et les envoient vers d'autres sources de données. Divers plugins sont disponibles pour gérer l'intégration des données avec différentes technologies telles que Redis, MongoDB, SAP, Snowflake, Splunk, etc.
Comment pouvez-vous utiliser Kafka ?
Il existe différentes façons de déployer Kafka :
-
Installation manuelle
Nous pouvons l'installer manuellement en utilisant les binaires Kafka pour le développement et les tests sur nos ordinateurs portables ou des conteneurs/serveurs pour une utilisation en production. Pour un déploiement minimal, nous avons besoin d'une instance de Zookeeper (si KRaft n'est pas utilisé), d'au moins une instance de courtier, et nous pouvons utiliser des scripts individuels disponibles dans les binaires Kafka pour créer des sujets, démarrer des producteurs et des consommateurs pour générer et consommer des données. Vous pouvez facilement commencer avec ce tutoriel de démarrage rapide d'Apache. Utilisation d'opérateurs
-
Utilisez des opérateurs
Pour déployer automatiquement des clusters Kafka et également ses fonctionnalités étendues (Kafka Connect, Kafka Bridge, Mirror Maker) sur Kubernetes/Openshift. Les options les plus populaires sont Strimzi et Confluent Operator. Les opérateurs prennent en charge plusieurs tâches manuelles lors de l'installation du cluster et facilitent également l'utilisation et la maintenance de votre cluster lorsqu'il s'agit de gérer les utilisateurs, les sujets, les modifications de configuration, etc.
-
Sur le Cloud
Utilisez des solutions SaaS hébergées sur le cloud telles que Confluent Cloud, Amazon MSK et autres.
Références
-
Apache Kafka Org: https://kafka.apache.org/
-
Strimzi: https://strimzi.io/
-
Confluent: https://www.confluent.io/
